Cloudflare 推出 isitagentready.com:你的網站對 AI Agent 準備好了嗎?
Cloudflare 在今年的 Agents Week(2026/04/17)悄悄丟出一個很有意思的工具:isitagentready.com。把任何網站的 URL 貼進去,它會給你一份報告,告訴你這個網站對 AI Agent 的相容程度是多少分,以及哪些地方可以改善。
我第一個反應是:這跟 Google PageSpeed Insights 的感覺很像,但評分的對象從「人類使用者」換成了「AI Agent」。這個轉換本身就是個有趣的訊號。
什麼是 Agent Readiness Score
分數範圍 0 到 100,分成三個等級(Cloudflare 未公開各等級的具體分數門檻):
| 等級 | 說明 |
|---|---|
| Basic | 基本功能到位,但多數 agent 標準未實作 |
| Emerging | 已採用部分新興標準 |
| Advanced | 全面支援,agent 可以順暢存取與互動 |
評分項目有四個(工具原始分類為五項,這裡將 API/Auth/MCP discovery 與 Commerce 合併為 Capabilities):
| 項目 | 說明 |
|---|---|
| Discoverability | 可發現性 |
| Content | 內容格式 |
| Bot Access Control | Bot 存取控制 |
| Capabilities | 能力宣告 |
四個評分維度
Discoverability — 讓 Agent 找得到你
這一塊最基礎,確保 agent 能發現你的網站結構:
robots.txt
是否存在,讓爬蟲知道哪些路徑可以存取。
sitemap.xml
提供結構化的網站地圖,幫助 agent 快速建立內容索引。
HTTP Link header
是否在 HTTP 回應中標示相關資源的位置,例如 Link: </sitemap.xml>; rel="sitemap" 或 Link: </api>; rel="describedby",讓 agent 不需要手動爬頁面就能發現結構。
大多數有在做 SEO 的網站這一塊應該沒問題。
Content — 讓 Agent 讀得懂你
Agent 不像人類瀏覽器,HTML 加一堆 JavaScript 對它來說很難消化。這個項目主要看:
Markdown 內容(Content Negotiation)
網站是否能在 agent 請求時提供 Markdown 格式的內容,而不是只有 HTML。Cloudflare 在 2026/03 推出了Markdown for Agents,協助網站自動轉換。
「Cloudflare 推出了一種方式,讓網站在 AI Agent 請求時自動提供乾淨的 Markdown 內容,讓 Agent 能直接讀取結構化文字,而不需要解析充滿 JavaScript 的 HTML。」
llms.txt
是否提供給 LLM 看的結構化文件索引。(llms-txt.org 規範)
「這是一個標準化網站提供 LLM 友善內容的提案:在網站根目錄放一個 /llms.txt 檔案,以 Markdown 格式撰寫,摘要說明網站的用途、結構與重要頁面,供語言模型參考。」
llms.txt 是一個新興慣例,放在網站根目錄,用簡潔的 Markdown 格式描述網站內容摘要,方便 LLM 快速理解整個網站的架構。我之前寫過一篇關於 llms.txt 的文章,有興趣可以參考。
Bot Access Control — 你要讓哪些 Bot 進來
robots.txt 本來是為了傳統爬蟲設計的,但現在 AI Bot 的種類爆炸,這個項目評估的是:
AI Bot 規則
robots.txt 是否有針對 AI 爬蟲(GPTBot、ClaudeBot 等)的明確允許或封鎖規則。Cloudflare 提供Managed robots.txt 服務,可以自動維護這份清單。
「Cloudflare 自動更新你的 robots.txt,加入指示主流 AI Bot 業者不得將你的內容用於模型訓練的規則,並隨著新 AI 爬蟲的出現持續維護這份清單。目前已有超過 380 萬個網域使用此服務。」
Content Signals
是否宣告了你的內容可以用於 AI 搜尋、但不能用於 AI 訓練之類的細部授權控制。這是 Cloudflare 提出的Content Signals Policy,在 robots.txt 加入 # content-signals 區塊,用三個選項(search、ai-input、ai-train)各別宣告允許與否。Cloudflare 在推出此功能時,已自動將 Content Signals 套用至上述 380 萬個使用 Managed robots.txt 的網域。
「網站管理者可以透過 robots.txt 中的機器可讀指令表達偏好,例如
Content-Signal: search=yes, ai-train=no,涵蓋三個維度:內容是否可用於搜尋、AI 生成回覆,或 AI 模型訓練。」
Content Signals Policy 是 Cloudflare 提出的私有擴充,尚未成為 IETF 正式標準,其他平台不一定支援或承認此語法。
Web Bot Auth
是否支援 Bot 的身份驗證。Bot 在發送請求時附上數位簽名,網站可以藉此確認對方是真正有授權的 agent,而不是冒充的爬蟲。(Cloudflare 技術說明、GitHub 實作)
「Web Bot Auth 是一種利用 HTTP 訊息中的加密簽名,驗證請求確實來自授權自動化 Bot 的認證方式,超越 IP 白名單的限制,有效防止偽冒。」
Web Bot Auth 是 Cloudflare 主導的提案,尚未經 IETF 標準化,目前生態系採用率極低。
Capabilities — 你能做什麼
這一塊最前沿,評估的是網站有沒有宣告自己支援哪些 agent 可以呼叫的能力:
API Catalog(RFC 9727)
在 /.well-known/api-catalog 提供機器可讀的 API 清單(Linkset JSON 格式),讓 agent 自動發現你有哪些 API 端點。
「本文件定義了 ‘api-catalog’ well-known URI,旨在促進已發布 API 的自動化發現與使用。對 /.well-known/api-catalog 發出請求後,將回傳一份 Linkset 文件,提供發布者 API 的相關資訊與連結。」 — RFC Editor
OAuth / OIDC Discovery(RFC 8414 / 9728)
RFC 8414 宣告授權伺服器端點(/.well-known/oauth-authorization-server),RFC 9728 宣告受保護資源的中繼資料,兩者合力讓 agent 完整走完 OAuth 授權流程,知道去哪裡取得 token、以及 token 能存取哪些資源。
MCP Server Card(SEP-1649)
在 /.well-known/mcp/server-card.json 提供 JSON 文件(路徑依 SEP-1649 草案,正式規格可能調整),讓 agent 在連線前就能知道這個 MCP server 支援什麼工具、需要什麼認證。(MCP 官方說明)SEP-1649 是 MCP 社群的正式提案編號(Specification Enhancement Proposal),截至 2026 年初尚未合併進核心規格,屬於草案階段。
「Server Card 是一份存放於 /.well-known/mcp-server-card 的 JSON 文件,在建立連線前即可描述一個 MCP Server:其識別資訊、支援的傳輸方式、協定版本以及連線指引,讓用戶端無需完整初始化握手即可自動完成設定。」
SEP-1649 尚未合併進 MCP 核心規格,為社群提案(Specification Enhancement Proposal)階段,規格細節仍可能調整。
Agent Skills
在 /.well-known/agent-skills/index.json 提供結構化描述,說明網站提供哪些 agent 可以執行的操作,包含 SKILL.md 文件或封裝好的 archive。(Cloudflare RFC 草稿)
「一種透過 .well-known URI 路徑前綴發現 Agent Skills 的機制,讓工具和 Agent 能以可預測的方式自動找到並取得某個組織提供的 Skills,無需任何預先設定。」
Agent Skills Discovery 是 Cloudflare 提出的 RFC 草稿,尚未進入任何正式標準組織的審查流程。
WebMCP
由 Google Chrome 團隊提出的瀏覽器 API,讓網站可以直接宣告結構化工具,瀏覽器環境中的 agent 就能以 searchFlights() 這類帶型別的函式呼叫網站功能,而不需要透過截圖分析再模擬點擊的慢速迴圈。Cloudflare 於 2026/04/15 在 Browser Run 中加入了對 WebMCP 的支援。(Cloudflare Changelog)
WebMCP 是 Google Chrome 團隊的提案,尚未成為 W3C 或瀏覽器廠商的正式標準,目前僅 Chrome 與 Cloudflare Browser Run 提供支援。
x402 Payment Protocol
讓 agent 可以代理付款。伺服器回傳 HTTP 402 並附上價格與收款地址,agent 自動完成付款後重新請求。(x402.org 規範)
「一個由 Coinbase 開發、基於 HTTP 402 ‘Payment Required’ 的開放式網際網路原生支付協定。若請求未附帶付款,伺服器回傳 402 及付款詳情;Agent 簽署穩定幣交易後重新請求——無需 API 金鑰、無需註冊,結算時間不到兩秒。」
x402 是 Coinbase 主導的開放協定,並非 IETF 標準,目前採用率接近零,且依賴穩定幣付款,在台灣有法規使用限制。
UCP(Universal Commerce Protocol)
Google 主導的電商代理協定,在 /.well-known/ucp 宣告結帳、帳號連結、訂單管理等能力,讓 agent 代理使用者完成購物流程。
「UCP 為代理商務定義了基礎構件——從發現、購買到購後體驗——讓整個生態系能透過單一標準互通,無需各自客製開發。」 — ucp.dev
UCP 是 Google 主導的提案,尚未進入正式標準化流程,目前採用率極低。
ACP Discovery
在 /.well-known/acp.json 宣告 Agent Communication Protocol 端點,讓其他 agent 知道怎麼跟這個網站的 agent 溝通。(ACP 規範)
「ACP 為 Agent 對 Agent(A2A)互動提供標準化框架,讓不同類型的 Agent 能透過簡單的 REST 端點,在不同環境中發現、協商並執行協作工作流程。」
ACP 仍是草案規格,尚未被主流平台或標準組織正式採納。
現況有多慘
Cloudflare 掃了 20 萬個頂級網站,結果很說明問題:
- 78% 的網站有
robots.txt,但大多數是為傳統爬蟲寫的 - 只有 4% 的網站有針對 AI 宣告使用偏好
- 支援 Markdown 內容的只有 3.9%
- 有 MCP Server Card 或 API Catalog 的網站,全球加起來不到 15 個
這個數字其實蠻震撼的。大家都在說 AI Agent 是未來,但網站基礎設施的準備程度完全跟不上。
對每個失敗的檢查項目,工具會自動產生一段 prompt,可以直接丟給 coding agent 去實作修正。這個設計很聰明,把「診斷」和「修復起點」連在一起。
為什麼這件事值得關注
以前 SEO 優化是「讓 Google 找得到你」,現在開始出現「讓 AI Agent 能操作你的網站」這個新命題。
差別在於:搜尋引擎主要是讀你的內容,Agent 則是要能對你的網站做事——登入、查資料、下訂單、呼叫 API。這需要的不只是可爬取的內容,還需要標準化的能力宣告和認證機制。
isitagentready.com 本質上是在推動這套生態系的標準化。Cloudflare 把評分工具做出來,等於是在告訴開發者:「這些標準的輪廓已經成形,值得開始關注。」
我的看法:先觀望,再出手
看完這份評分清單,可以發現一個共同特徵:大部分項目仍在草案階段,從 SEP-1649、WebMCP、Content Signals 到 ACP,幾乎都是各家廠商自己推的提案,尚未進入正式標準組織的審查流程,規格隨時可能調整甚至被廢棄。
在這種情況下,我並不建議為了衝高分數就一頭熱全部實作。工程資源有限,追著草案走的風險是:花了時間做出來,標準卻往另一個方向走,最後變成技術債。
比較務實的做法是分兩層處理:
- 現在就值得做的:
robots.txt加入 AI bot 規則、提供 Markdown 內容、補上llms.txt。這些成本低、沒有相容性風險,而且 AI 爬蟲今天就在抓你的網站。 - 持續觀望的:MCP Server Card、WebMCP、x402、UCP、ACP。等到有兩三個主流平台正式支援、或是進入 IETF / W3C 正式審查,再評估是否跟進。
isitagentready.com 這個工具的價值,不在於讓你馬上把分數拉滿,而是讓你知道這個生態系目前的輪廓長什麼樣子,等方向更明確的時候,你才知道該往哪裡走。
自己試試
直接去 isitagentready.com 貼你的網站看看得幾分,報告很清楚。低分項目也有對應的改善建議,是個很快能得到回饋的工具。
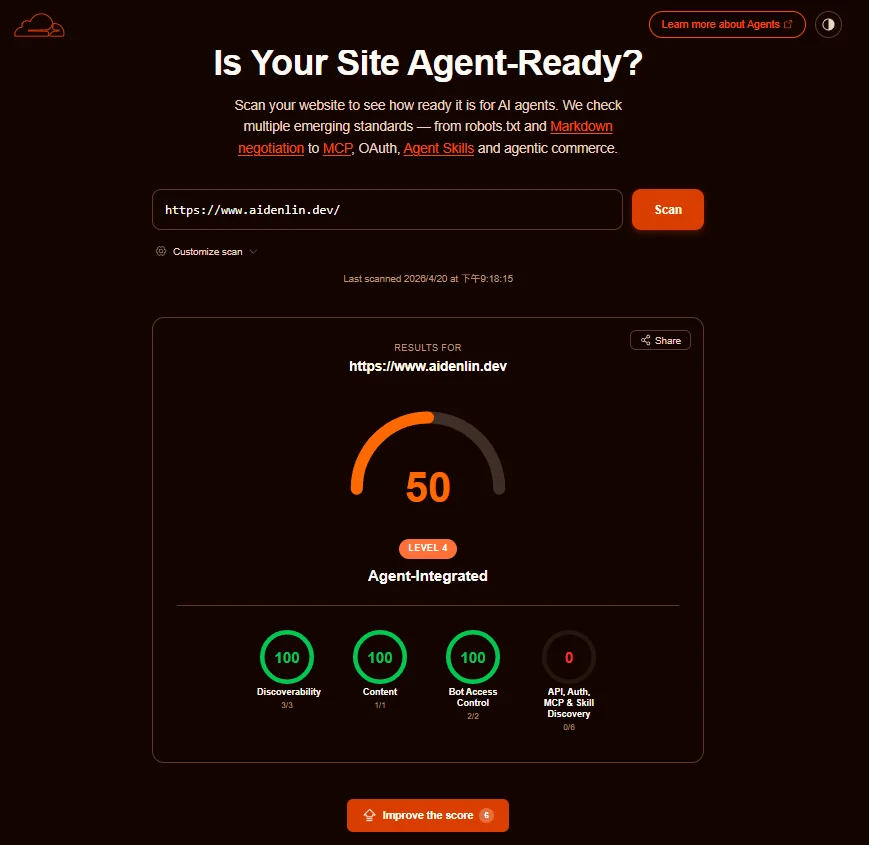
前三項(Discoverability、Content、Bot Access Control)都是滿分,因為不是電商所以最後一個項目不適用。
資料來源:
留言